Experiment cockpit
Shipwright
An autonomous product loop that compares options, routes the best work, ships code, and publishes the evidence.
observe:ab_consensus_work_order:pricing-page-watch
Scored model votes across judge runs.
2 blockers still visible.
Evidence Bundle
Artifact manifest is complete with 30 required evidence files present.
{kind=link}
Bundle complete
Missing 0
Health attention
Required 30
Ready 15
Attention 4
GitHub Adoption
Reusable Project Setup
Installer output, repo settings, provider readiness, and website publishing are tracked as one onboarding path.
shipwright github-setup --repo matthoffner/shipwright --workflow .github/workflows/shipwright-dogfood.yml --schedule-mode dry_run --dispatch-dry-run --publish-site false
gh workflow run .github/workflows/shipwright-dogfood.yml -f mode=dry_run -f publish_site=false
Shipwright GitHub adoption wiring is ready.
Setup helper has not been recorded for this repo yet.
Fresh reusable GitHub adoption smoke passed.
Shipwright can start, but 1 readiness warning should be reviewed before schedules cook.
Codex is configured for OpenRouter with openai/gpt-5.1-codex-mini.
Vercel accepted the latest site deploy.
Product model
Autonomous Product Loop
Shipwright is the loop. A/B consensus is the decision/evidence layer. Lanes are execution modes, not the product concept.
-
1
Observe
Read product history, runtime evidence, blockers, and current state.
-
2
Compare
Use A/B consensus, judges, votes, and screenshots to choose a direction.
-
3
Route
Turn the selected direction into one lane-specific work order.
-
4
Ship
Let the autonomous worker make bounded code changes and verify them.
-
5
Report
Publish the changelog, audit trail, deploy status, and website evidence.
Decision / evidence layer
A/B consensus compares variants and produces a work order before Shipwright routes it to a lane.
Current winner: Variant A / Experiment cockpit. Evidence comes from model judges, human votes, Playwright captures, runtime probes, and readiness gates.
Lane routing
Active lane: Observe
Observe owns this run; 1 fallback lane remains eligible and 3 lanes are blocked or off.
Active 1
Eligible 1
Blocked 2
Off 1
Route map
Observe owns this run; Intake is the first fallback.
Intake fallback -> Build blocked -> Review blocked -> Release disabled -> Observe active
Step 5/5
Fallback Intake
Blocked 2
Off 1
Work starts here for this run.
Use this lane if the owner blocks.
2 lanes need signal or repair before routing.
1 lane is disabled by configuration.
-
1
Intake fallback
Self-dogfood runtime work is eligible from the repository roadmap and config
-
2
Build blocked
No failing check signal is available in the local scaffold
-
3
Review blocked
No review comment or maintainer mention signal is available in the local scaffold
-
4
Release disabled
Lane 'release' is disabled in shipwright.yml
-
5
Observe active
A/B consensus work order 1 is ready for dogfood execution: Watch: Pricing Page Experiment
eligible
Intake
turn roadmap, config, and product notes into implementation work
- Next action
- intake:advance_runtime
- Why now
- Self-dogfood runtime work is eligible from the repository roadmap and config
- Priority
- 80
Evidence
- action_status: eligible
- candidate_priority: 80
- selected: false
blocked
Build
repair failing checks and local verification failures
- Next action
- build:repair_verification
- Why now
- No failing check signal is available in the local scaffold
- Priority
- none
Evidence
- action_status: blocked
- candidate_priority: none
- selected: false
blocked
Review
respond to review comments and maintainer mentions
- Next action
- review:address_feedback
- Why now
- No review comment or maintainer mention signal is available in the local scaffold
- Priority
- none
Evidence
- action_status: blocked
- candidate_priority: none
- selected: false
off
Release
surface ready changes and unblock release decisions
- Next action
- release:prepare_delivery
- Why now
- Lane 'release' is disabled in shipwright.yml
- Priority
- none
Evidence
- action_status: blocked
- candidate_priority: none
- selected: false
active
Observe
improve reports, journals, website output, and run evidence
- Next action
- observe:ab_consensus_work_order:pricing-page-watch
- Why now
- A/B consensus work order 1 is ready for dogfood execution: Watch: Pricing Page Experiment
- Priority
- 60
Evidence
- action_status: eligible
- candidate_priority: 60
- selected: true
Evidence Index
Run Evidence
attention4 evidence components need attention; Observe owns this run; 1 fallback lane remains eligible and 3 lanes are blocked or off.
Next Actions
- Pricing Page Experiment: needs more signal
- Product history Focused Section Size: fail - Largest changelog section has 15 entries; DevBox-style sections stay small and outcome-specific.
- Let the dogfood workflow deploy site/ to Vercel and record the result.
- Run Shipwright Dogfood in non-dry-run mode to capture worker execution evidence.
- Run Shipwright Dogfood in non-dry-run mode to capture worker contract evidence.
Lane Board
readyObserve owns this run; 1 fallback lane remains eligible and 3 lanes are blocked or off.
Evidence
- outcome: dry_run
- mode: dry_run
- selected_lane: observe
- selected_task: observe:ab_consensus_work_order:pricing-page-watch
Next Actions
- Execute observe:ab_consensus_work_order:pricing-page-watch in the Observe lane.
- Clear blocker for build: No failing check signal is available in the local scaffold
- Clear blocker for review: No review comment or maintainer mention signal is available in the local scaffold
Current State
attentionAutonomous Dogfood Runtime is the latest product outcome; 0 work orders ready, 2 blocked targets across 2 failing checks.
Evidence
- ready_work_orders: 0
- blocked: 2
- blocking_checks: 2
Next Actions
- Pricing Page Experiment: needs more signal
- Product history Focused Section Size: fail - Largest changelog section has 15 entries; DevBox-style sections stay small and outcome-specific.
A/B Consensus Queue
readyShipwright Site is ready for implementation with Variant A; dogfood, visual, and consensus evidence are aligned.
Evidence
- work_orders: 1
- ship: 2
- watch: 1
- blocked: 0
Next Actions
- Complete the primary unblock action for Pricing Page Experiment: Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- Regenerate the report and confirm the item leaves blocked status or records a narrower blocker.
Doctor
attentionShipwright can start, but 1 readiness warning should be reviewed before schedules cook.
Evidence
- mode: dry_run
- workspace: /home/runner/work/shipwright/shipwright
- workflow: .github/workflows/shipwright-dogfood.yml
- config: shipwright.yml
Next Actions
- Let the dogfood workflow deploy site/ to Vercel and record the result.
Adoption
readyShipwright GitHub adoption wiring is ready.
Evidence
- workflow: .github/workflows/shipwright-dogfood.yml
- workflow_template: local_dogfood
- config: shipwright.yml
- targets: shipwright.targets.json
Adoption Smoke
readyFresh reusable GitHub adoption smoke passed.
Evidence
- repo: matthoffner/shipwright
- workspace: /tmp/shipwright-adoption-smoke-oSzOdh
- template: reusable
- steps: 4
Next Actions
- Use this same install, github-setup, and manual dry-run path in target GitHub projects.
Project Dependencies
readyProject dependencies installed with npm ci.
Evidence
- workspace: /home/runner/work/shipwright/shipwright
- package_manager: npm
- package_name: shipwright
- lockfile: package-lock.json
Browser Install
readyPlaywright browser chromium is installed for surface captures.
Evidence
- runtime_dir: /home/runner/work/shipwright/shipwright
- browser: chromium
- with_deps: true
- command: npx playwright install --with-deps chromium
CI Run
readyShipwright CI run completed.
Evidence
- mode: dry_run
- preflight: passed
- work_cycle: passed
- finalize: passed
Next Actions
- Run shipwright orchestrate with site/ab-consensus-queue.json.
- Run Shipwright in autonomous or yolo mode to allow changelog and git publishing.
- Run shipwright ci-finalize to refresh report and deploy evidence.
CI Preflight
readyShipwright CI preflight completed and wrote setup evidence.
Evidence
- mode: dry_run
- targets: 3
- steps: 11
- project_dependencies: passed / Project dependencies installed with npm ci.
Next Actions
- Run shipwright orchestrate with site/ab-consensus-queue.json.
CI Work Cycle
readyShipwright CI work cycle completed in dry_run mode.
Evidence
- mode: dry_run
- steps: 6
- write_prerequisites: skipped
- publish: skipped
Next Actions
- Run Shipwright in autonomous or yolo mode to allow changelog and git publishing.
- Run shipwright ci-finalize to refresh report and deploy evidence.
Safety
readyShipwright dry_run mode has the required safety controls.
Evidence
- mode: dry_run
- checks: 7
- pass: 7
- warn: 0
Verification
readyVerification was skipped because Shipwright is running in dry_run mode.
Evidence
- mode: dry_run
- commands: 3
- skipped: dry_run
Next Actions
- Run Shipwright in autonomous or yolo mode to verify post-worker changes.
Deployment
readyVercel accepted the latest site deploy.
Evidence
- provider: vercel
- state: deployed
- VERCEL_TOKEN: configured
- VERCEL_ORG_ID: configured
Next Actions
- Verify the live Vercel site renders the latest site artifacts.
CI Finalize
readyCI finalize passed; publish_site true; deploy configured_unverified.
Evidence
- publish_site: true
- deploy_deferred: true
- deploy_state: configured_unverified
- doctor_state: needs_attention
Git Publish
readyGit publishing skipped because Shipwright is running in dry_run mode.
Evidence
- mode: dry_run
- pushed: false
Next Actions
- Run Shipwright in autonomous or yolo mode when changes should be committed and pushed.
Codex Provider
readyCodex is configured for OpenRouter with openai/gpt-5.1-codex-mini.
Evidence
- provider: openrouter
- model: openai/gpt-5.1-codex-mini
- wire_api: responses
- OPENROUTER_API_KEY: configured
Next Actions
- Run Codex with OPENROUTER_API_KEY available in the environment.
Codex Worker
attentionNo Codex worker run has been recorded for this report.
Evidence
- codex-worker-status.json missing
Next Actions
- Run Shipwright Dogfood in non-dry-run mode to capture worker execution evidence.
Worker Contract
attentionNo Codex worker contract trace has been recorded for this report.
Evidence
- commands: 0
- first edit command index: -1
Next Actions
- Run Shipwright Dogfood in non-dry-run mode to capture worker contract evidence.
Current State
Autonomous Dogfood Runtime is the latest product outcome; 0 work orders ready, 2 blocked targets across 2 failing checks.
Journal-independent digest built from product history, consensus, runtime, credential, and screenshot evidence.
A/B accepted2/3
Work orders0
Blocked targets2
Failing checks2
Deploy blocked0
Rendered targets3/3
Captured surfaces3/3
Current State Details Work orders, blockers, next actions, and evidence sources.
Work Orders
Consensus
- Watch: Pricing Page Experiment 80%
Pricing Page Experiment is 80% ready; collect one more signal before promotion.
Ready
Signals
- Shipwright A/B Lab: rendered 3/3
- Onboarding Flow Experiment: rendered 3/3
- Pricing Page Experiment: rendered 3/3
- Shipwright A/B Lab: captured visual evidence
- Onboarding Flow Experiment: captured visual evidence
- Pricing Page Experiment: captured visual evidence
Blocked
Blockers
- Pricing Page Experiment: needs more signal
- Product history Focused Section Size: fail - Largest changelog section has 15 entries; DevBox-style sections stay small and outcome-specific.
Next
Actions
- Split oversized sections into narrower dated outcomes before the website treats product history as healthy.
- Add lightweight page events once Shipwright has real recurring users.
- Compare first-viewport comprehension after each generated site change.
- Capture real usage events after the first UI slice ships.
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
Evidence
Sources
- Derived from CHANGELOG.md product history, not raw journal prose.
- Uses target runtime, credential, screenshot, dogfood plan, and A/B consensus artifacts.
- Uses deployment status evidence so the website cannot silently drift behind CI.
- Run journal remains audit evidence only.
UI Consensus
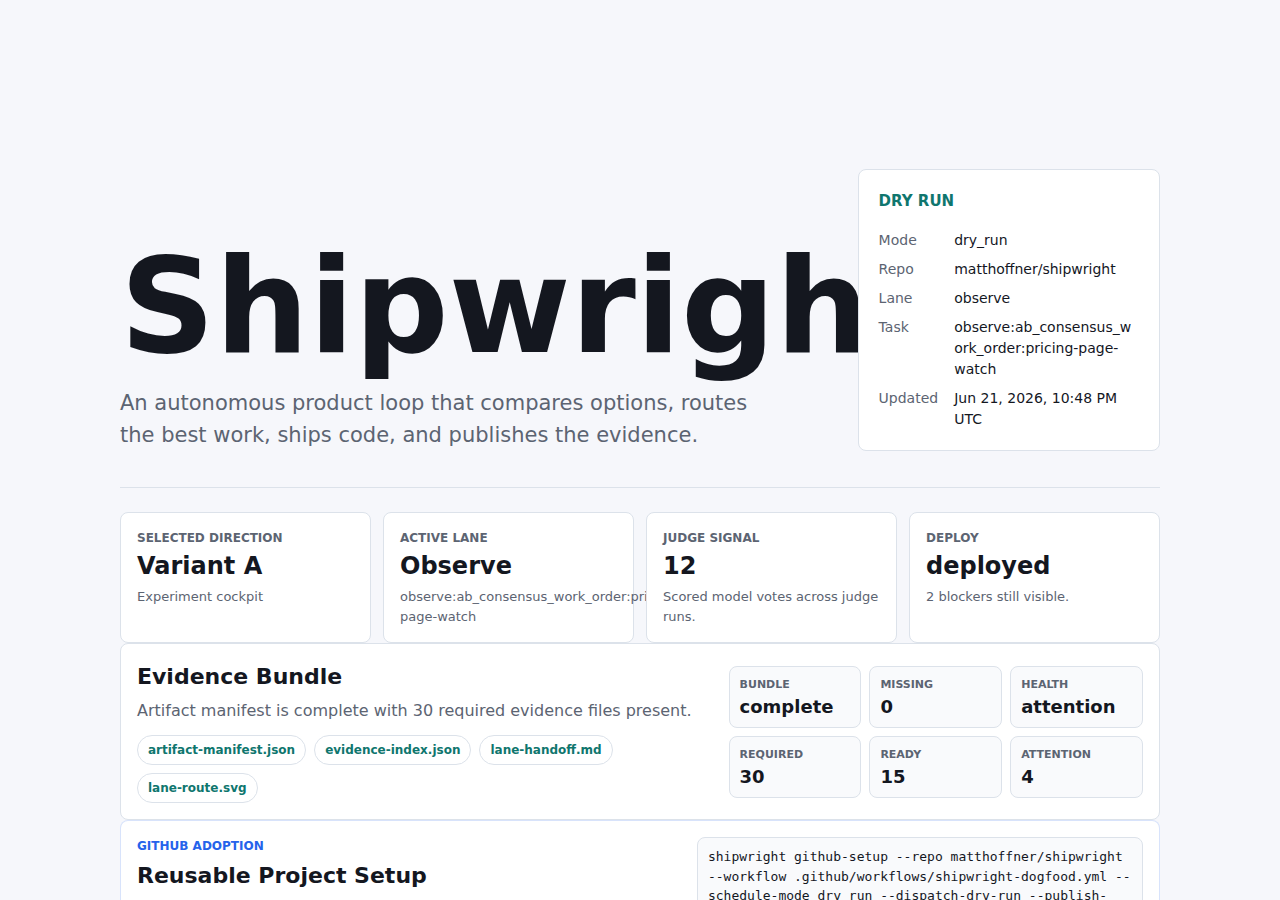
Variant A: Experiment cockpit
Should Shipwright lead with a toggleable experiment cockpit or a fast winner board?
Variant A wins because Shipwright is becoming an autonomous A/B platform: generate two UI versions, capture them with Playwright, ask multiple LLMs to judge, let humans vote, then hand the winner to an agent.
Consensus handoff
Render a first-class Variant A / Variant B toggle on the website.
Score
9.1 / 6.7Margin 2.4; high confidence; threshold 1.5
Judges
43 selected the winning variant.
Experiment subjects
4Shipwright keeps built-in UI subjects in the same judge-and-vote comparison set.
Variant Toggle The A/B presentation candidates Shipwright can hand to a worker.
Variant Toggle
Experiment cockpit
Lead with a toggleable A/B workspace: Variant A, Variant B, Playwright evidence, model-judge scorecards, and human vote state.
Strengths
- Makes each autonomous UI run inspectable without reading raw logs.
- Turns the website into a product control surface for A/B decisions.
- Gives model judges and humans the same evidence packet.
Risks
- Needs strong hierarchy so the cockpit does not feel like raw CI output.
- Needs real Playwright captures for each generated variant before claims are trusted.
Fast winner board
Lead with the winning variant, summarized rationale, and one next action before showing the deeper judge evidence.
Strengths
- Lets a busy operator see what won immediately.
- Keeps the first viewport lighter for first-time readers.
Risks
- Can hide dissent and weak evidence behind a premature recommendation.
- Makes it harder for humans to audit why the losing variant lost.
Consensus Cockpit Target tabs, evidence, and implementation handoffs.
UI consensus target summary
One-card-per-target view of the A/B winner, vote confidence, runtime proof, screenshot capture, and first worker action.
Shipwright Site
Variant A clears the A/B threshold by 2.4 weighted points.
- Votes
- 3/3 majority, 0 dissent
- Runtime
- rendered 3/3
- Capture
- captured
- First Action
- Promote Variant A: Experiment cockpit as the default website layout.
Onboarding Flow Experiment
Variant A clears the A/B threshold by 1.2 weighted points.
- Votes
- 3/3 majority, 0 dissent
- Runtime
- rendered 3/3
- Capture
- captured
- First Action
- Promote Variant A: Guided checklist for Onboarding Flow Experiment.
Pricing Page Experiment
The margin is 0.9, below the 1 point threshold, so more signal is required.
- Votes
- 3/3 majority, 0 dissent
- Runtime
- rendered 3/3
- Capture
- captured
- First Action
- Promote Variant B: Judge-proof pricing for Pricing Page Experiment.
Shipwright Site
Variant A: Experiment cockpit
Variant A clears the A/B threshold by 2.4 weighted points.
Readiness
Shipwright A/B Lab rendered 3/3 expected signals and can be used as consensus evidence.
Signals
- credential: not required
- runtime: rendered
- start attempt: not attempted
- matched signals: 3/3
Next Actions
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Surface Snapshot
Shipwright
Variant A: Experiment cockpit winner
Lead with a toggleable A/B workspace: Variant A, Variant B, Playwright evidence, model-judge scorecards, and human vote state.
Risk: Needs strong hierarchy so the cockpit does not feel like raw CI output.
Variant B: Fast winner board
Lead with the winning variant, summarized rationale, and one next action before showing the deeper judge evidence.
Risk: Can hide dissent and weak evidence behind a premature recommendation.
LLM Judges
- GPT-5.1 Judge chose Variant A at 9/10: The cockpit keeps variants, evidence, model reasoning, and the worker handoff in one decision packet.
- Claude Sonnet Judge chose Variant A at 8/10: A is more honest about uncertainty because it shows the loser, dissent, and evidence gaps before shipping.
- Gemini Judge chose Variant B at 7/10: B is easier to scan, but it needs the cockpit below the fold to keep the decision trustworthy.
- Human Panel chose Variant A at 8/10: People need the toggle and vote record before trusting an autonomous winner.
LLM Judge Matrix
Consensus Response Packet
Should Shipwright lead with a toggleable experiment cockpit or a fast winner board?
3/3 judges selected Variant A. No dissent recorded for this consensus packet.
Evidence Checklist
- Decision status: accepted
- Playwright evidence: captured
- Runtime evidence: rendered
- Strongest criterion: Playwright Evidence +3
- Dissent: none
| Criterion | Winner | Runner-up | Delta |
|---|---|---|---|
| LLM Judge Agreement | 9 | 7 | +2 |
| Playwright Evidence | 9 | 6 | +3 |
| Human Vote Clarity | 9 | 6 | +3 |
| Agent Handoff | 9 | 8 | +1 |
| Judge | Vote | Alignment | Confidence | Evidence |
|---|---|---|---|---|
| gpt-5.1-codex-mini Judge | Variant A | majority | 8/10 | judge-run:judge-run-landing-shipwright-site, source:openrouter, Variant A weighted score, Variant A strength, Variant B risk |
| gemini-2.5-flash-lite Judge | Variant A | majority | 8/10 | judge-run:judge-run-landing-shipwright-site, source:openrouter, Variant A thesis, Variant B risk |
| claude-haiku-4.5 Judge | Variant A | majority | 9/10 | judge-run:judge-run-landing-shipwright-site, source:openrouter, Variant A thesis: Makes each autonomous UI run inspectable without reading raw logs, Variant A strength: Gives model judges and humans the same evidence packet, Variant A LLM Judge Agreement: 9/10 - The model judges can inspect both variants and explain agreement or dissent, Variant B risk: Can hide dissent and weak evidence behind a premature recommendation, Variant B Agent Handoff: 8/10 - weaker evidence context can make autonomous work brittle |
Onboarding Flow Experiment
Variant A: Guided checklist
Variant A clears the A/B threshold by 1.2 weighted points.
Readiness
Onboarding Flow Experiment rendered 3/3 expected signals and can be used as consensus evidence.
Signals
- credential: not required
- runtime: rendered
- start attempt: not attempted
- matched signals: 3/3
Next Actions
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Surface Snapshot
Untitled surface
npm run check
npm run report
Variant A: Guided checklist winner
Lead onboarding with a concrete sequence of setup, first experiment, judge review, and publish steps.
Risk: Can feel too procedural for experienced users who already know the flow.
Variant B: Autonomous summary
Lead onboarding with what Shipwright already inferred and one high-confidence next action.
Risk: Can hide important setup gaps if the summary is too confident.
LLM Judges
- GPT-5.1 Judge chose Variant A at 9/10: Onboarding Flow Experiment should optimize for the experiment job named by its surface: Built-in onboarding UI variant.
- Claude Sonnet Judge chose Variant A at 8/10: The winning variant creates clearer product intent and a better autonomous handoff.
- Gemini Judge chose Variant B at 7/10: The alternate keeps useful pressure on visual simplicity and first-impression quality.
- Human Panel chose Variant A at 8/10: The group vote favors the direction with the clearest implementation and review path.
LLM Judge Matrix
Consensus Response Packet
Should onboarding lead with a guided checklist or an autonomous summary?
3/3 judges selected Variant A. No dissent recorded for this consensus packet.
Evidence Checklist
- Decision status: accepted
- Playwright evidence: captured
- Runtime evidence: rendered
- Strongest criterion: Implementation Fit +2
- Dissent: none
| Criterion | Winner | Runner-up | Delta |
|---|---|---|---|
| Experiment Fit | 9 | 8 | +1 |
| Judgeability | 8 | 7 | +1 |
| Implementation Fit | 9 | 7 | +2 |
| Evidence Quality | 8 | 7 | +1 |
| Judge | Vote | Alignment | Confidence | Evidence |
|---|---|---|---|---|
| gpt-5.1-codex-mini Judge | Variant A | majority | 8/10 | judge-run:judge-run-target-onboarding-flow, source:openrouter, Variant A thesis, Variant B risk |
| gemini-2.5-flash-lite Judge | Variant A | majority | 8/10 | judge-run:judge-run-target-onboarding-flow, source:openrouter, Variant A thesis, Variant B risk |
| claude-haiku-4.5 Judge | Variant A | majority | 9/10 | judge-run:judge-run-target-onboarding-flow, source:openrouter, Variant A weighted score 8.6 vs Variant B 7.4, Variant A Judgeability 8/10 vs Variant B 7/10, Variant B risk: hidden setup gaps if summary too confident, Variant A strength: makes first successful run obvious, Variant B Implementation Fit 7/10 requires accurate state inference |
Pricing Page Experiment
Variant B: Judge-proof pricing
The margin is 0.9, below the 1 point threshold, so more signal is required.
Readiness
Pricing Page Experiment rendered 3/3 expected signals and can be used as consensus evidence.
Signals
- credential: not required
- runtime: rendered
- start attempt: not attempted
- matched signals: 3/3
Next Actions
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Surface Snapshot
Untitled surface
npm run check
npm run report
Variant A: Simple plan comparison
Lead pricing with straightforward plans, limits, and the first practical upgrade point.
Risk: Underplays the differentiator: autonomous evidence-backed shipping.
Variant B: Judge-proof pricing winner
Lead pricing with proof: experiments run, judges consulted, human votes collected, and winners shipped.
Risk: Requires stronger examples before it beats a simple comparison table.
LLM Judges
- GPT-5.1 Judge chose Variant B at 9/10: Pricing Page Experiment should optimize for the experiment job named by its surface: Built-in pricing UI variant.
- Claude Sonnet Judge chose Variant B at 8/10: The winning variant creates clearer product intent and a better autonomous handoff.
- Gemini Judge chose Variant A at 7/10: The alternate keeps useful pressure on visual simplicity and first-impression quality.
- Human Panel chose Variant B at 8/10: The group vote favors the direction with the clearest implementation and review path.
LLM Judge Matrix
Consensus Response Packet
Should pricing lead with a simple plan comparison or proof from judge outcomes?
3/3 judges selected Variant B. No dissent recorded for this consensus packet.
Evidence Checklist
- Decision status: needs_more_signal
- Playwright evidence: captured
- Runtime evidence: rendered
- Strongest criterion: Evidence Quality +2
- Dissent: none
| Criterion | Winner | Runner-up | Delta |
|---|---|---|---|
| Experiment Fit | 9 | 8 | +1 |
| Judgeability | 9 | 8 | +1 |
| Implementation Fit | 8 | 9 | -1 |
| Evidence Quality | 9 | 7 | +2 |
| Judge | Vote | Alignment | Confidence | Evidence |
|---|---|---|---|---|
| gpt-5.1-codex-mini Judge | Variant B | majority | 7/10 | judge-run:judge-run-target-pricing-page, source:openrouter, Variant B thesis, Variant B Evidence Quality |
| gemini-2.5-flash-lite Judge | Variant B | majority | 9/10 | judge-run:judge-run-target-pricing-page, source:openrouter, Variant B thesis, Variant B strength, Variant B risk, Variant A risk |
| claude-haiku-4.5 Judge | Variant B | majority | 9/10 | judge-run:judge-run-target-pricing-page, source:openrouter, Variant B weighted score 8.9 vs Variant A 8.0, Variant B evidence quality 9/10 vs Variant A 7/10, Variant A risk: underplays autonomous evidence-backed shipping differentiator, Variant B strength: connects price to outcomes and makes platform defensible, Variant B experiment fit 9/10 aligns with Shipwright's core differentiator |
Scoring Details Rubric, judge votes, and next actions.
A/B Options
Variant A: Experiment cockpit selected
Lead with a toggleable A/B workspace: Variant A, Variant B, Playwright evidence, model-judge scorecards, and human vote state.
Strength: Makes each autonomous UI run inspectable without reading raw logs.
Risk: Needs strong hierarchy so the cockpit does not feel like raw CI output.
Variant B: Fast winner board
Lead with the winning variant, summarized rationale, and one next action before showing the deeper judge evidence.
Strength: Lets a busy operator see what won immediately.
Risk: Can hide dissent and weak evidence behind a premature recommendation.
Weighted Rubric
Variant A 9.1
Experiment cockpit
- LLM Judge Agreement: 9/10, weighted 2.7
- Playwright Evidence: 9/10, weighted 2.3
- Human Vote Clarity: 9/10, weighted 2.3
- Agent Handoff: 9/10, weighted 1.8
Variant B 6.7
Fast winner board
- LLM Judge Agreement: 7/10, weighted 2.1
- Playwright Evidence: 6/10, weighted 1.5
- Human Vote Clarity: 6/10, weighted 1.5
- Agent Handoff: 8/10, weighted 1.6
Decision threshold: Variant A clears the A/B threshold by 2.4 weighted points.
LLM Judge Agreement 30%
Multiple model judges can compare the variants and explain the same winner.
Playwright Evidence 25%
The decision is grounded in rendered UI capture instead of prose alone.
Human Vote Clarity 25%
A group of people can vote, see dissent, and understand how their input affects the result.
Agent Handoff 20%
The selected variant produces a concrete implementation prompt for an autonomous worker.
LLM Judges
GPT-5.1 Judge 9/10
Variant A / reasoning model. The cockpit keeps variants, evidence, model reasoning, and the worker handoff in one decision packet.
Claude Sonnet Judge 8/10
Variant A / product critique. A is more honest about uncertainty because it shows the loser, dissent, and evidence gaps before shipping.
Gemini Judge 7/10
Variant B / visual comparison. B is easier to scan, but it needs the cockpit below the fold to keep the decision trustworthy.
Human Panel 8/10
Variant A / group vote. People need the toggle and vote record before trusting an autonomous winner.
Next Actions
Render a first-class Variant A / Variant B toggle on the website.
Keep model judges, human votes, and Playwright evidence in the same decision packet.
Generate worker prompts from the winning variant only after evidence gates pass.
Judge Runs
Shipwright Site
3/3 model judges selected Variant A for Shipwright Site.
Screenshots
- Variant A: judge-runs/landing-shipwright-site/variant-A.png
- Variant B: judge-runs/landing-shipwright-site/variant-B.png
Votes
- gpt-5.1-codex-mini Judge: Variant A (8/10)
- gemini-2.5-flash-lite Judge: Variant A (8/10)
- claude-haiku-4.5 Judge: Variant A (9/10)
Shipwright A/B Lab
3/3 model judges selected Variant A for Shipwright A/B Lab.
Screenshots
- Variant A: judge-runs/target-shipwright-site/variant-A.png
- Variant B: judge-runs/target-shipwright-site/variant-B.png
Votes
- gpt-5.1-codex-mini Judge: Variant A (8/10)
- gemini-2.5-flash-lite Judge: Variant A (8/10)
- claude-haiku-4.5 Judge: Variant A (9/10)
Onboarding Flow Experiment
3/3 model judges selected Variant A for Onboarding Flow Experiment.
Screenshots
- Variant A: judge-runs/target-onboarding-flow/variant-A.png
- Variant B: judge-runs/target-onboarding-flow/variant-B.png
Votes
- gpt-5.1-codex-mini Judge: Variant A (8/10)
- gemini-2.5-flash-lite Judge: Variant A (8/10)
- claude-haiku-4.5 Judge: Variant A (9/10)
Pricing Page Experiment
3/3 model judges selected Variant B for Pricing Page Experiment.
Screenshots
- Variant A: judge-runs/target-pricing-page/variant-A.png
- Variant B: judge-runs/target-pricing-page/variant-B.png
Votes
- gpt-5.1-codex-mini Judge: Variant B (7/10)
- gemini-2.5-flash-lite Judge: Variant B (9/10)
- claude-haiku-4.5 Judge: Variant B (9/10)
A/B Test Consensus
2/3 A/B consensus items are shippable; 0 blocked; 1 need watch.
Operator queue derived from A/B tests, consensus lanes, judge-panel judge matrices, and dogfood readiness.
Watch: Pricing Page Experiment
Pricing Page Experiment is 80% ready; collect one more signal before promotion.
Consensus Handoff Packet
Improve Shipwright's report, queue, or target metadata handoff for Pricing Page Experiment; do not edit the target app source.
Metric
- Buyer confidence: a visitor can connect price to shipped A/B outcomes and judge evidence.
Runtime Proof
- The margin is 0.9, below the 1 point threshold, so more signal is required. The rendered surface was captured and can be reviewed alongside the scorecard.
Target Metadata
- Run state: watch; dogfood ready; visual captured; promotion needs_more_signal.
- Operator metric: Buyer confidence: a visitor can connect price to shipped A/B outcomes and judge evidence.
- Consensus: Variant B; 3 majority / 0 dissent; score delta +0.9.
- Next action: Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- Verification: npm run check
Operator Trust
- Run state: watch; dogfood ready; visual captured; promotion needs_more_signal.
Source Boundary
- .shipwright/targets/pricing-page is dogfood evidence only; durable changes for this work order belong in Shipwright files.
First Edit
- Start in src/report.ts, src/ab-consensus-queue.ts, and their focused tests before inspecting any generated site artifact.
Worker Edit Recipe
- Real command 1: run the required rg command from the execution prompt.
- Real command 2: inspect one focused src/report.ts or src/ab-consensus-queue.ts range, 160 lines or less.
- Real command 3: inspect one final adjacent source range only if needed; do not run another search.
- Real command 4: edit src/ab-consensus-queue.ts, src/report.ts, or the matching focused test.
- Change shape: make the Pricing Page Experiment target handoff clearer without editing .shipwright/targets/pricing-page.
- Verify with npm run check before finishing.
Verify Next
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
Experiment Packet
Allocation
- Variant A: 50% - Simple plan comparison
- Variant B: 50% - Judge-proof pricing
Events
- shipwright_ab_test_exposed
- shipwright_ab_test_primary_signal
- shipwright_ab_test_guardrail_signal
- shipwright_ab_test_decision
Missing Signals
- accepted decision threshold
Proof
- Gate passed: Visual
- Gate passed: Dogfood
- Gate passed: Judge Matrix
- Gate needs work: Decision: watch
- Gate needs work: Promotion: watch
Acceptance
- Complete the primary unblock action for Pricing Page Experiment: Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- Regenerate the report and confirm the item leaves blocked status or records a narrower blocker.
Failed Gates
- Decision: watch
- Promotion: watch
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Shipwright Site
Shipwright Site is ready for implementation with Variant A; dogfood, visual, and consensus evidence are aligned.
Recommended Next
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
- landing-live-behavior: Add lightweight page events once Shipwright has real recurring users.
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
- curl -fsSL https://shipwright-seven.vercel.app/ab-tests.json
Clear First
No items in this lane.
Ready To Ship
Shipwright Site
Time-to-action: can a returning operator identify the next useful Shipwright move?
A/B variant comparison
- Winning
- Experiment cockpit (9.1)
- Runner-up
- Fast winner board (6.7)
- Votes
- A:3 / B:1
- Why
- Lead with a toggleable A/B workspace: Variant A, Variant B, Playwright evidence, model-judge scorecards, and human vote state.
- Risk
- Can hide dissent and weak evidence behind a premature recommendation.
Experiment Packet
Allocation
- Variant A: 50% - Experiment cockpit
- Variant B: 50% - Fast winner board
Events
- shipwright_ab_test_exposed
- shipwright_ab_test_primary_signal
- shipwright_ab_test_guardrail_signal
- shipwright_ab_test_decision
Gates
- Decision accepted with high confidence and +2.4 margin.
- Promotion ready for build
- Visual Captured Shipwright A/B Lab at https://shipwright-seven.vercel.app.
- Dogfood Shipwright A/B Lab is ready.
- Judge Matrix 3/3 judges aligned with 0 dissent.
Next
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
- landing-live-behavior: Add lightweight page events once Shipwright has real recurring users.
Criteria
- Experiment Fit: 9/6 (+3)
- Judgeability: 8/7 (+1)
- Implementation Fit: 9/6 (+3)
- Evidence Quality: 9/5 (+4)
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
- curl -fsSL https://shipwright-seven.vercel.app/ab-tests.json
Onboarding Flow Experiment
Activation clarity: a new user can identify the first experiment, judge review, and publish path.
A/B variant comparison
- Winning
- Guided checklist (8.6)
- Runner-up
- Autonomous summary (7.4)
- Votes
- A:3 / B:1
- Why
- Lead onboarding with a concrete sequence of setup, first experiment, judge review, and publish steps.
- Risk
- Can hide important setup gaps if the summary is too confident.
Experiment Packet
Allocation
- Variant A: 50% - Guided checklist
- Variant B: 50% - Autonomous summary
Events
- shipwright_ab_test_exposed
- shipwright_ab_test_primary_signal
- shipwright_ab_test_guardrail_signal
- shipwright_ab_test_decision
Gates
- Decision accepted with medium confidence and +1.2 margin.
- Promotion ready for build
- Visual Captured Onboarding Flow Experiment at targets/onboarding-flow.html.
- Dogfood Onboarding Flow Experiment is ready.
- Judge Matrix 3/3 judges aligned with 0 dissent.
Next
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
- onboarding-flow-live-behavior: Capture real usage events after the first UI slice ships.
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Criteria
- Experiment Fit: 9/8 (+1)
- Judgeability: 8/7 (+1)
- Implementation Fit: 9/7 (+2)
- Evidence Quality: 8/7 (+1)
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Watch
Pricing Page Experiment
Buyer confidence: a visitor can connect price to shipped A/B outcomes and judge evidence.
A/B variant comparison
- Winning
- Judge-proof pricing (8.9)
- Runner-up
- Simple plan comparison (8)
- Votes
- A:1 / B:3
- Why
- Lead pricing with proof: experiments run, judges consulted, human votes collected, and winners shipped.
- Risk
- Underplays the differentiator: autonomous evidence-backed shipping.
Experiment Packet
Allocation
- Variant A: 50% - Simple plan comparison
- Variant B: 50% - Judge-proof pricing
Events
- shipwright_ab_test_exposed
- shipwright_ab_test_primary_signal
- shipwright_ab_test_guardrail_signal
- shipwright_ab_test_decision
Missing Signals
- accepted decision threshold
Gates
- Decision needs more signal with low confidence and +0.9 margin.
- Promotion needs more signal
- Visual Captured Pricing Page Experiment at targets/pricing-page.html.
- Dogfood Pricing Page Experiment is ready.
- Judge Matrix 3/3 judges aligned with 0 dissent.
Next
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- pricing-page-live-behavior: Capture real usage events after the first UI slice ships.
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Criteria
- Experiment Fit: 9/8 (+1)
- Judgeability: 9/8 (+1)
- Implementation Fit: 8/9 (-1)
- Evidence Quality: 9/7 (+2)
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Queue Next Actions
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
- landing-live-behavior: Add lightweight page events once Shipwright has real recurring users.
- landing-first-impression: Compare first-viewport comprehension after each generated site change.
- Keep this subject in the default experiment path.
Shipwright Site
Should Shipwright lead with a toggleable experiment cockpit or a fast winner board?
Primary metricTime-to-action: can a returning operator identify the next useful Shipwright move?
Score9.1 / 6.7
VotesVariant A: 3, Variant B: 1
Playwright evidencecaptured / 1
Decision Rule
- Variant A clears the A/B threshold by 2.4 weighted points. The rendered surface was captured and can be reviewed alongside the scorecard.
- Threshold 1.5; margin 2.4; status accepted.
- Synthetic product, design, engineering, and operations judges until live traffic exists.
Experiment Packet
- Assignment: synthetic judge
- Readout: accepted / high
- shipwright-site selects Variant A with high confidence; 3 observed signals and 0 missing signals.
- Promote Variant A when promotion gates stay green for Time-to-action: can a returning operator identify the next useful Shipwright move?.
Allocation
- Variant A: 50% - Experiment cockpit
- Variant B: 50% - Fast winner board
Event Contract
shipwright_ab_test_exposedshipwright_ab_test_primary_signalshipwright_ab_test_guardrail_signalshipwright_ab_test_decision
Observed Signals
- decision threshold accepted
- visual evidence captured
- runtime matched 3/3 signals
Missing Signals
- No missing signals.
Playwright Evidence
- Captured Shipwright A/B Lab at https://shipwright-seven.vercel.app.
- The rendered surface was captured and can be reviewed alongside the scorecard.
- runtime matched 3/3 signals
Image: captures/shipwright-site.png
Guardrails
- First-time comprehension of what Shipwright is becoming.
- Auditability of the decision through JSON artifacts.
- Visibility of dissent and next actions.
Variant A: Experiment cockpit
Lead with a toggleable A/B workspace: Variant A, Variant B, Playwright evidence, model-judge scorecards, and human vote state.
Audience: Returning operators and agents reviewing autonomous runs.
Experience: Evidence-first console with status, changelog, consensus, and next actions.
Signal: More readers can explain the selected lane and next action without opening logs.
Variant B: Fast winner board
Lead with the winning variant, summarized rationale, and one next action before showing the deeper judge evidence.
Audience: First-time readers trying to understand the product story.
Experience: Narrative journal-led page centered on the latest run.
Signal: More readers understand the story, but fewer can act on the current state.
Next Actions
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
Promotion Packet
- Owner: Shipwright website worker
- Rollout: Keep the generated site deterministic; publish Variant A as the default until live traffic exists.
- Sample: Synthetic consensus with multiple LLM judges, a human panel, and visual evidence status: captured.
- Ship: Variant A clears the A/B threshold by 2.4 weighted points. Ship when the generated site exposes the A/B toggle, LLM judges, human votes, and Playwright evidence together.
- Stop: Stop promotion if the first viewport hides current run state, if JSON artifacts stop being generated, or if the page regresses into raw journal text.
Implementation Brief
- Promote Variant A: Experiment cockpit as the default website layout.
- Keep the changelog as product history and the journal as compact audit evidence.
- Preserve dissent in the page so the fast-winner-board risk stays visible.
- Make the A/B consensus artifact good enough for another worker to implement without reading source code.
Instrumentation
- shipwright_ab_test_exposed: A user or dogfood worker sees either variant.
- shipwright_ab_test_primary_signal: The primary metric can be evaluated for the viewed variant.
- shipwright_ab_test_decision: Variant A is promoted, rejected, or sent back for more signal.
Evidence Gaps
- landing-live-behavior (follow up): The winner is based on offline consensus, not live visitor behavior. Add lightweight page events once Shipwright has real recurring users.
- landing-first-impression (follow up): Design dissent says the product story still needs to survive the evidence-first layout. Compare first-viewport comprehension after each generated site change.
Verify
npm run checknode dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.jsonnpm run verify:intakecurl -fsSL https://shipwright-seven.vercel.app/ab-tests.json
Worker Prompt
Use site/ab-tests.json as the source of truth. Improve the Shipwright website by implementing the winning A/B consensus direction while preserving product history, dissent, and machine-readable artifacts.
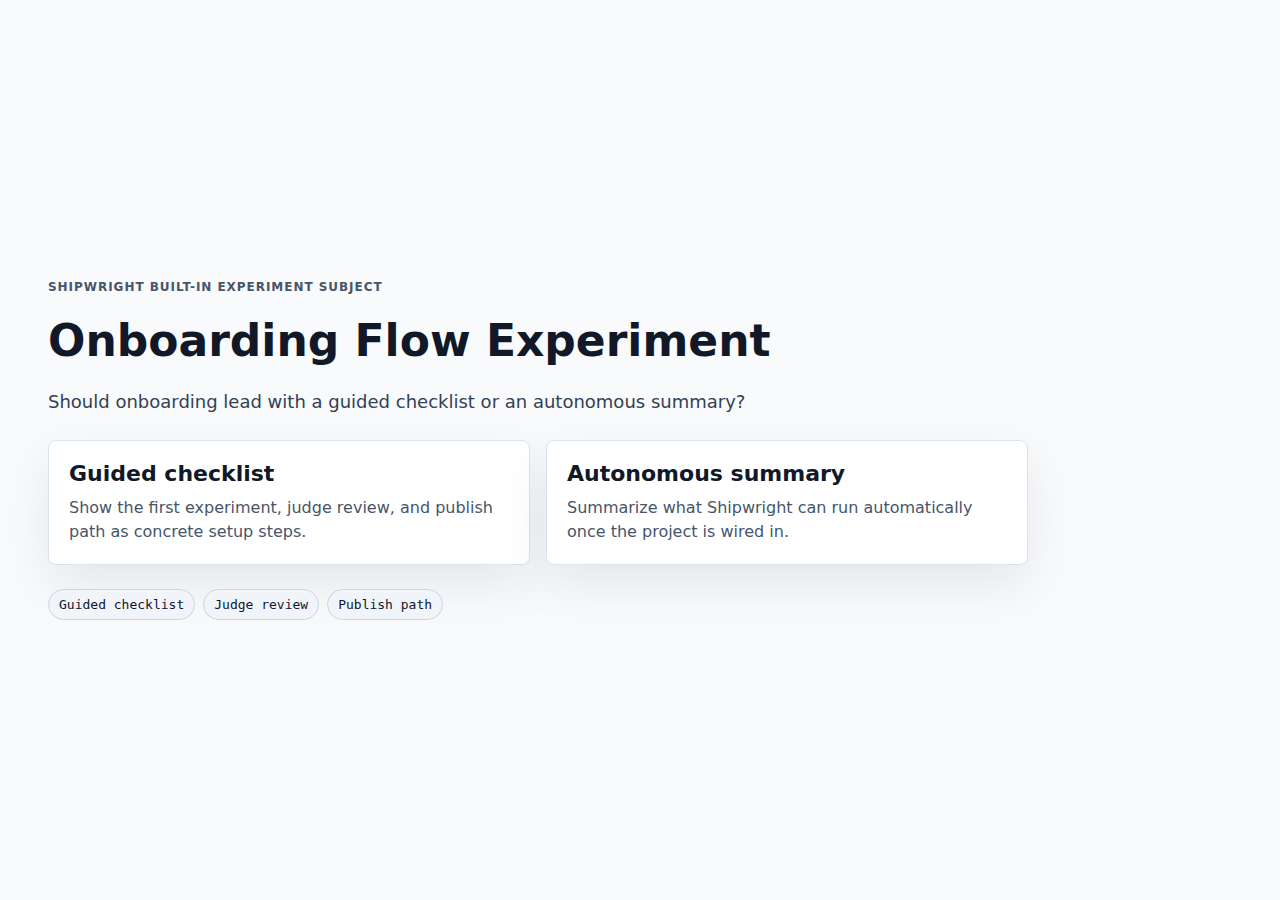
Onboarding Flow Experiment
Should onboarding lead with a guided checklist or an autonomous summary?
Primary metricActivation clarity: a new user can identify the first experiment, judge review, and publish path.
Score8.6 / 7.4
VotesVariant A: 3, Variant B: 1
Playwright evidencecaptured / 1
Decision Rule
- Variant A clears the A/B threshold by 1.2 weighted points. The rendered surface was captured and can be reviewed alongside the scorecard.
- Threshold 1; margin 1.2; status accepted.
- Synthetic app-specific judges derived from the target consensus rubric.
Experiment Packet
- Assignment: experiment subject
- Readout: accepted / medium
- onboarding-flow selects Variant A with medium confidence; 3 observed signals and 0 missing signals.
- Promote Variant A when promotion gates stay green for Activation clarity: a new user can identify the first experiment, judge review, and publish path..
Allocation
- Variant A: 50% - Guided checklist
- Variant B: 50% - Autonomous summary
Event Contract
shipwright_ab_test_exposedshipwright_ab_test_primary_signalshipwright_ab_test_guardrail_signalshipwright_ab_test_decision
Observed Signals
- decision threshold accepted
- visual evidence captured
- runtime matched 3/3 signals
Missing Signals
- No missing signals.
Playwright Evidence
- Captured Onboarding Flow Experiment at targets/onboarding-flow.html.
- The rendered surface was captured and can be reviewed alongside the scorecard.
- runtime matched 3/3 signals
Image: captures/onboarding-flow.png
Guardrails
- The winning direction preserves the target app's declared primary job.
- The losing direction's strongest risk remains visible before implementation.
- Future dogfood runs have concrete UI signals to inspect.
Variant A: Guided checklist
Lead onboarding with a concrete sequence of setup, first experiment, judge review, and publish steps.
Audience: New operators setting up their first autonomous A/B run.
Experience: Guided checklist for setup, first experiment, judge review, and publish steps.
Signal: New users can complete the first run without reading docs or raw logs.
Variant B: Autonomous summary
Lead onboarding with what Shipwright already inferred and one high-confidence next action.
Audience: Returning operators who want Shipwright to infer the next step.
Experience: Autonomous summary that explains inferred state and recommends one action.
Signal: Operators move faster when setup assumptions are already correct.
Next Actions
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
Promotion Packet
- Owner: Onboarding Flow Experiment experiment worker
- Rollout: Build as a generated UI variant first, then promote the winner after judge and human-vote evidence stays coherent.
- Sample: Synthetic experiment judges plus visual evidence status: captured.
- Ship: Variant A clears the A/B threshold by 1.2 weighted points. Ship when the subject has captured Playwright evidence and no blocking evidence gaps remain.
- Stop: Stop promotion if the screenshots are missing, the judge matrix loses consensus, or the losing variant's primary risk becomes a real blocker.
Implementation Brief
- Promote Variant A: Guided checklist for Onboarding Flow Experiment.
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
- Primary target job: Built-in onboarding UI variant.
- Keep the losing variant's strongest risk visible in the implementation notes.
Instrumentation
- shipwright_ab_test_exposed: A user or dogfood worker sees either variant.
- shipwright_ab_test_primary_signal: The primary metric can be evaluated for the viewed variant.
- shipwright_ab_test_decision: Variant A is promoted, rejected, or sent back for more signal.
Evidence Gaps
- onboarding-flow-live-behavior (follow up): The current decision is an offline consensus, not a live product experiment. Capture real usage events after the first UI slice ships.
Verify
npm run checknode dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.jsonnpm run verify:intake
Worker Prompt
Use site/ab-tests.json, site/consensus-matrix.json, and site/surface-captures.json to implement Variant A for Onboarding Flow Experiment. Preserve the primary job "Built-in onboarding UI variant" and verify the generated screenshots before shipping.
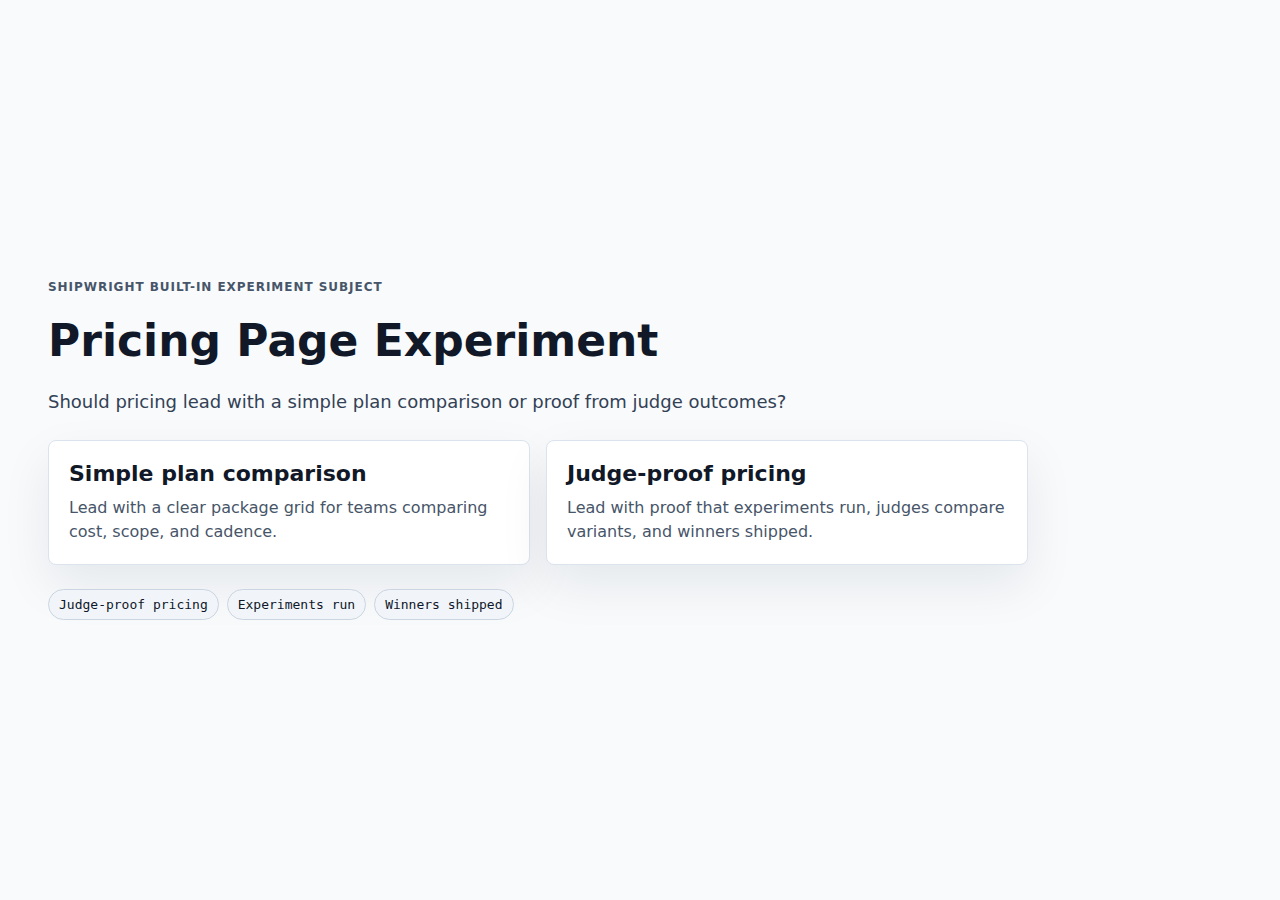
Pricing Page Experiment
Should pricing lead with a simple plan comparison or proof from judge outcomes?
Primary metricBuyer confidence: a visitor can connect price to shipped A/B outcomes and judge evidence.
Score8.9 / 8
VotesVariant A: 1, Variant B: 3
Playwright evidencecaptured / 1
Decision Rule
- The margin is 0.9, below the 1 point threshold, so more signal is required. The rendered surface was captured and can be reviewed alongside the scorecard.
- Threshold 1; margin 0.9; status needs more signal.
- Synthetic app-specific judges derived from the target consensus rubric.
Experiment Packet
- Assignment: experiment subject
- Readout: needs more signal / low
- pricing-page selects Variant B with low confidence; 2 observed signals and 1 missing signal.
- Hold Variant B until missing signals are resolved.
Allocation
- Variant A: 50% - Simple plan comparison
- Variant B: 50% - Judge-proof pricing
Event Contract
shipwright_ab_test_exposedshipwright_ab_test_primary_signalshipwright_ab_test_guardrail_signalshipwright_ab_test_decision
Observed Signals
- visual evidence captured
- runtime matched 3/3 signals
Missing Signals
- accepted decision threshold
Playwright Evidence
- Captured Pricing Page Experiment at targets/pricing-page.html.
- The rendered surface was captured and can be reviewed alongside the scorecard.
- runtime matched 3/3 signals
Image: captures/pricing-page.png
Guardrails
- The winning direction preserves the target app's declared primary job.
- The losing direction's strongest risk remains visible before implementation.
- Future dogfood runs have concrete UI signals to inspect.
Variant A: Simple plan comparison
Lead pricing with straightforward plans, limits, and the first practical upgrade point.
Audience: Buyers scanning pricing before they understand the platform deeply.
Experience: Simple plan comparison with limits, usage, and the first upgrade moment.
Signal: Visitors understand cost and constraints quickly.
Variant B: Judge-proof pricing
Lead pricing with proof: experiments run, judges consulted, human votes collected, and winners shipped.
Audience: Buyers evaluating whether autonomous experimentation is worth paying for.
Experience: Outcome proof cards showing experiments run, judges consulted, votes collected, and winners shipped.
Signal: Visitors connect pricing to evidence-backed shipping outcomes.
Next Actions
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
Promotion Packet
- Owner: Pricing Page Experiment experiment worker
- Rollout: Build as a generated UI variant first, then promote the winner after judge and human-vote evidence stays coherent.
- Sample: Synthetic experiment judges plus visual evidence status: captured.
- Ship: The margin is 0.9, below the 1 point threshold, so more signal is required. Ship when the subject has captured Playwright evidence and no blocking evidence gaps remain.
- Stop: Stop promotion if the screenshots are missing, the judge matrix loses consensus, or the losing variant's primary risk becomes a real blocker.
Implementation Brief
- Promote Variant B: Judge-proof pricing for Pricing Page Experiment.
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- Primary target job: Built-in pricing UI variant.
- Keep the losing variant's strongest risk visible in the implementation notes.
Instrumentation
- shipwright_ab_test_exposed: A user or dogfood worker sees either variant.
- shipwright_ab_test_primary_signal: The primary metric can be evaluated for the viewed variant.
- shipwright_ab_test_decision: Variant B is promoted, rejected, or sent back for more signal.
Evidence Gaps
- pricing-page-live-behavior (follow up): The current decision is an offline consensus, not a live product experiment. Capture real usage events after the first UI slice ships.
Verify
npm run checknode dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.jsonnpm run verify:intake
Worker Prompt
Use site/ab-tests.json, site/consensus-matrix.json, and site/surface-captures.json to implement Variant B for Pricing Page Experiment. Preserve the primary job "Built-in pricing UI variant" and verify the generated screenshots before shipping.
Dogfood Status Current readiness across the built-in experiment subjects.
3/3 experiment subjects are ready; 0 blocked; 0 need watch.
Single dogfood view derived from target inspection, credentials, runtime starts, rendered probes, surface captures, and consensus handoffs.
Shipwright A/B Lab
Shipwright A/B Lab has rendered runtime, captured surface, and ready consensus evidence.
- Target
- remote
- Credential
- not_required
- Runtime start
- not_recorded
- Plan
- self
Next
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
Evidence
- remote url configured: https://shipwright-seven.vercel.app
- No repository credential is required for this target.
- Fetched https://shipwright-seven.vercel.app; matched 3/3 expected runtime signals.
- Captured Shipwright A/B Lab at https://shipwright-seven.vercel.app.
Onboarding Flow Experiment
Onboarding Flow Experiment has rendered runtime, captured surface, and ready consensus evidence.
- Target
- metadata_only
- Credential
- not_required
- Runtime start
- not_recorded
- Plan
- self
Next
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
- onboarding-flow-live-behavior: Capture real usage events after the first UI slice ships.
Evidence
- target is generated by this repository
- No repository credential is required for this target.
- Fetched targets/onboarding-flow.html; matched 3/3 expected runtime signals.
- Captured Onboarding Flow Experiment at targets/onboarding-flow.html.
Pricing Page Experiment
Pricing Page Experiment has rendered runtime, captured surface, and ready consensus evidence.
- Target
- metadata_only
- Credential
- not_required
- Runtime start
- not_recorded
- Plan
- self
Next
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- pricing-page-live-behavior: Capture real usage events after the first UI slice ships.
Evidence
- target is generated by this repository
- No repository credential is required for this target.
- Fetched targets/pricing-page.html; matched 3/3 expected runtime signals.
- Captured Pricing Page Experiment at targets/pricing-page.html.
Experiment Next Actions
- Keep this subject in the default experiment path.
- Use this rendered runtime as the baseline for the next UI consensus comparison.
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
- landing-live-behavior: Add lightweight page events once Shipwright has real recurring users.
Consensus Board Promotion lanes and worker prompts for the next implementation pass.
2/3 UI consensus subjects are ready for build; 1 need more signal.
A/B consensus board for deciding what a worker can implement now versus what needs runtime, credential, or screenshot evidence first.
Ready For Build
Consensus winners with accepted decision rules and captured visual evidence.
Shipwright Site
Time-to-action: can a returning operator identify the next useful Shipwright move?
Next
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Onboarding Flow Experiment
Activation clarity: a new user can identify the first experiment, judge review, and publish path.
Next
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
- onboarding-flow-live-behavior: Capture real usage events after the first UI slice ships.
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Needs More Signal
Consensus winners blocked by missing screenshots, runtime evidence, or credential setup.
Pricing Page Experiment
Buyer confidence: a visitor can connect price to shipped A/B outcomes and judge evidence.
Next
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- pricing-page-live-behavior: Capture real usage events after the first UI slice ships.
Verify
- npm run check
- node dist/cli.js capture-surfaces --registry shipwright.targets.json --site-dir site --output metrics/surface-captures.json
- npm run verify:intake
Board Next Actions
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- pricing-page-live-behavior: Capture real usage events after the first UI slice ships.
- Render a first-class Variant A / Variant B toggle on the website.
- Keep model judges, human votes, and Playwright evidence in the same decision packet.
- Generate worker prompts from the winning variant only after evidence gates pass.
- landing-live-behavior: Add lightweight page events once Shipwright has real recurring users.
Codex Worker Autonomous write result, changed files, and failure evidence.
Codex Worker Run
not_recordedNo Codex worker run has been recorded for this report.
No changed files recorded yet.
Evidence
- codex-worker-status.json missing
Next Actions
- Run Shipwright Dogfood in non-dry-run mode to capture worker execution evidence.
Worker Contract Whether the autonomous worker stayed inside the command contract.
Codex Worker Contract
unknownNo Codex worker contract trace has been recorded for this report.
Evidence
- commands: 0
- first edit command index: -1
No command trace captured yet.
Next Actions
- Run Shipwright Dogfood in non-dry-run mode to capture worker contract evidence.
UI Experiments Poll questions, responses, and synthesis outputs.
Shipwright A/B Lab UI Consensus Poll
Autonomous A/B experiment console. Should the experiment console optimize for operator confidence or fast winner selection?
Winner Variant A: Evidence-first surface.
Readiness remote
Surface rendered
Poll Questions
- Should the experiment console optimize for operator confidence or fast winner selection? Use Variant A: Evidence-first surface.
- What should block Shipwright from implementing the winning UI direction? The losing variant may still be better for first-time users or marketing pages.
Responses
- GPT-5.1 Judge selected Variant A at 9/10.
- Claude Sonnet Judge selected Variant A at 8/10.
- Gemini Judge selected Variant B at 7/10.
- Human Panel selected Variant A at 8/10.
Synthesis
- 3/4 judges selected Variant A.
- Shipwright should run Shipwright A/B Lab as an A/B subject with Variant A: Evidence-first surface.
- Use the captured rendered surface signals as the baseline for the next UI comparison.
Surface Signals
- No surface signals captured.
Source Model
- No source model extracted yet.
Onboarding Flow Experiment UI Consensus Poll
Built-in onboarding UI variant. Should onboarding lead with a guided checklist or an autonomous summary?
Winner Variant A: Guided checklist.
Readiness metadata only
Surface metadata only
Poll Questions
- Should onboarding lead with a guided checklist or an autonomous summary? Use Variant A: Guided checklist.
- What should block Shipwright from implementing the winning UI direction? The losing variant may still be better for first-time users or marketing pages.
Responses
- GPT-5.1 Judge selected Variant A at 9/10.
- Claude Sonnet Judge selected Variant A at 8/10.
- Gemini Judge selected Variant B at 7/10.
- Human Panel selected Variant A at 8/10.
Synthesis
- 3/4 judges selected Variant A.
- Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
- Use declared subject metadata until generated UI evidence is available.
Surface Signals
- npm run check
- npm run report
Source Model
- No source model extracted yet.
Pricing Page Experiment UI Consensus Poll
Built-in pricing UI variant. Should pricing lead with a simple plan comparison or proof from judge outcomes?
Winner Variant B: Judge-proof pricing.
Readiness metadata only
Surface metadata only
Poll Questions
- Should pricing lead with a simple plan comparison or proof from judge outcomes? Use Variant B: Judge-proof pricing.
- What should block Shipwright from implementing the winning UI direction? The losing variant may still be better for operators who need dense controls.
Responses
- GPT-5.1 Judge selected Variant B at 9/10.
- Claude Sonnet Judge selected Variant B at 8/10.
- Gemini Judge selected Variant A at 7/10.
- Human Panel selected Variant B at 8/10.
Synthesis
- 3/4 judges selected Variant B.
- Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
- Use declared subject metadata until generated UI evidence is available.
Surface Signals
- npm run check
- npm run report
Source Model
- No source model extracted yet.
UI Surfaces Rendered or source-level surface evidence.
shipwright-site
Title: Shipwright
Headings: none
Signals: none
onboarding-flow
Title: unknown
Headings: none
Signals: npm run check, npm run report
pricing-page
Title: unknown
Headings: none
Signals: npm run check, npm run report
Runtime Evidence Runtime URLs, matched signals, and missing signals.
Shipwright A/B Lab
renderedURL: https://shipwright-seven.vercel.app
Start: npm run report
Matched: 3/3
Matched Signals
- A/B Test Consensus
- LLM Judges
- Variant Toggle
Next Actions
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Onboarding Flow Experiment
renderedURL: targets/onboarding-flow.html
Start: none
Matched: 3/3
Matched Signals
- Guided checklist
- Judge review
- Publish path
Next Actions
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Pricing Page Experiment
renderedURL: targets/pricing-page.html
Start: none
Matched: 3/3
Matched Signals
- Judge-proof pricing
- Experiments run
- Winners shipped
Next Actions
- Use this rendered runtime as the baseline for the next UI consensus comparison.
Runtime Start Attempts What Shipwright tried to start for each subject.
No runtime start attempts recorded yet.
Doctor One-command readiness for imported GitHub projects.
Shipwright Doctor
needs attentionShipwright can start, but 1 readiness warning should be reviewed before schedules cook.
Workspace: /home/runner/work/shipwright/shipwright
Evidence
- mode: dry_run
- workspace: /home/runner/work/shipwright/shipwright
- workflow: .github/workflows/shipwright-dogfood.yml
- config: shipwright.yml
- targets: shipwright.targets.json
- pass: 4
Next Actions
- Let the dogfood workflow deploy site/ to Vercel and record the result.
GitHub Adoption
passShipwright GitHub adoption wiring is ready.
Evidence
- workflow: .github/workflows/shipwright-dogfood.yml
- workflow_template: local_dogfood
- config: shipwright.yml
- targets: shipwright.targets.json
- pass: 10
- warn: 0
Safety Policy
passShipwright dry_run mode has the required safety controls.
Evidence
- mode: dry_run
- checks: 7
- pass: 7
- warn: 0
- fail: 0
Verification Plan
passVerification is configured with 3 commands.
Evidence
- command: npm run build
- command: npm test
- command: npm run report
Codex Provider
passCodex is configured for OpenRouter with openai/gpt-5.1-codex-mini.
Evidence
- provider: openrouter
- model: openai/gpt-5.1-codex-mini
- wire_api: responses
- OPENROUTER_API_KEY: configured
- config_path: /home/runner/.codex/config.toml
Website Deploy
warnVercel deploy secrets are configured, but this report has not observed a completed deploy.
Evidence
- provider: vercel
- state: configured_unverified
- VERCEL_TOKEN: configured
- VERCEL_ORG_ID: configured
- VERCEL_PROJECT_ID: configured
- message: Website deploy deferred until ci-run writes top-level status and refreshes final evidence.
Next Actions
- Let the dogfood workflow deploy site/ to Vercel and record the result.
Adoption Reusable GitHub Actions onboarding and evidence wiring.
GitHub Adoption
passShipwright GitHub adoption wiring is ready.
Workflow: .github/workflows/shipwright-dogfood.yml
Evidence
- workflow: .github/workflows/shipwright-dogfood.yml
- workflow_template: local_dogfood
- config: shipwright.yml
- targets: shipwright.targets.json
- pass: 10
- warn: 0
GitHub Actions Workflow
passFound Shipwright workflow at .github/workflows/shipwright-dogfood.yml.
Evidence
- workflow: .github/workflows/shipwright-dogfood.yml
Workflow Triggers
passWorkflow supports manual and scheduled runs.
Evidence
- workflow_dispatch: configured
- schedule: configured
Workflow Permissions
passWorkflow has the permissions required to write evidence and read checks.
Evidence
- contents: write
- actions: read
- checks: read
Workflow Commands
passWorkflow runs the full Shipwright adoption, evidence, worker, publish, and deploy-gate loop through ci-run.
Evidence
- command: ci-run
- phase_chain: delegated_to_ci_run
Shipwright Runtime
passDogfood workflow builds Shipwright in-repo and uses the local CLI.
Evidence
- runtime_mode: local_dogfood
- workflow: .github/workflows/shipwright-dogfood.yml
- cli: node dist/cli.js
Evidence Upload
passWorkflow uploads website and machine-readable evidence artifacts.
Evidence
- upload-artifact: v7
- site/**
- metrics/**/*.json
- metrics/**/*.jsonl
- metrics/**/*.md
- metrics/**/*.log
Adoption Runbook
passSHIPWRIGHT.md documents manual validation, secrets, variables, and evidence review.
Evidence
- runbook: SHIPWRIGHT.md
- manual dry run: documented
- OPENROUTER_API_KEY: documented
- SHIPWRIGHT_SCHEDULE_MODE: documented
- evidence-index: documented
- artifact-manifest: documented
Shipwright Config
passshipwright.yml is parseable and points at a GitHub repository with verification.
Evidence
- provider: github
- repo: matthoffner/shipwright
- mode: dry_run
- target_branches: main
- verification: npm run build && npm test && npm run report
Target Registry
passTarget registry has 3 experiment subjects.
Evidence
- targets: 3
- shipwright-site: shipwright/static-site
- onboarding-flow: shipwright/static-site
- pricing-page: shipwright/static-site
Package Verification
passPackage scripts and Shipwright verification commands line up.
Evidence
- script: build
- script: test
- script: check
- verification: npm run build && npm test && npm run report
Project Dependencies Package manager detection and install evidence for imported projects.
Project Dependencies
installedProject dependencies installed with npm ci.
Workspace: /home/runner/work/shipwright/shipwright
Install: npm ci
Evidence
- workspace: /home/runner/work/shipwright/shipwright
- package_manager: npm
- package_name: shipwright
- lockfile: package-lock.json
- install_command: npm ci
- steps: 1
Project dependency install
passedCommand: npm ci
Project dependencies were already installed before this command.
Browser Install Playwright browser readiness for surface capture and judge evidence.
Browser Install
installedPlaywright browser chromium is installed for surface captures.
Runtime: /home/runner/work/shipwright/shipwright
Command: npx playwright install --with-deps chromium
Evidence
- runtime_dir: /home/runner/work/shipwright/shipwright
- browser: chromium
- with_deps: true
- command: npx playwright install --with-deps chromium
- exit_code: 0
- signal: null
Safety YOLO and autonomous mode policy readiness.
Safety Policy
passShipwright dry_run mode has the required safety controls.
Evidence
- mode: dry_run
- checks: 7
- pass: 7
- warn: 0
- fail: 0
Hard Stops
passRequired hard stops are configured.
Evidence
- hard_stop: secret_detected
- hard_stop: production_config_change
- hard_stop: explicit_human_block
- hard_stop: budget_exhausted
Forbidden Paths
passForbidden path coverage includes environment, secret, and production paths.
Evidence
- forbidden_path: .env
- forbidden_path: secrets/**
- forbidden_path: infra/prod/**
Human Approval Gates
passHuman approval is required for schedule and destructive changes.
Evidence
- approval: merge
- approval: schedule_update
- approval: destructive_change
Verification Commands
passVerification commands provide build/test/check coverage.
Evidence
- verification: npm run build
- verification: npm test
- verification: npm run report
Change Limits
passAutonomous change limits are bounded.
Evidence
- maxOpenChanges: 3
- maxChangesPerRun: 1
- maxCommentsPerRun: 3
- maxIterations: 20
Target Branch
passTarget branches are explicit and include main.
Evidence
- target_branch: main
Mode Readiness
passdry_run mode has the lanes required for the loop.
Evidence
- mode: dry_run
- enabled_lanes: build, review, intake, observe
Verification Post-worker command gate and durable status evidence.
Verification Gate
skippedVerification was skipped because Shipwright is running in dry_run mode.
Workspace: /home/runner/work/shipwright/shipwright
Evidence
- mode: dry_run
- commands: 3
- skipped: dry_run
Next Actions
- Run Shipwright in autonomous or yolo mode to verify post-worker changes.
npm run build
skippedSkipped because Shipwright is running in dry_run mode.
npm test
skippedSkipped because Shipwright is running in dry_run mode.
npm run report
skippedSkipped because Shipwright is running in dry_run mode.
Deployment Vercel deploy state and next action.
Vercel Site
deployedProvider: vercel
URL: https://shipwright-seven.vercel.app
Vercel accepted the latest site deploy.
Required Secrets
- VERCEL_TOKEN: configured
- VERCEL_ORG_ID: configured
- VERCEL_PROJECT_ID: configured
Evidence
- provider: vercel
- state: deployed
- VERCEL_TOKEN: configured
- VERCEL_ORG_ID: configured
- VERCEL_PROJECT_ID: configured
- message: Final refreshed CI evidence is projected for the Vercel deploy.
Next Actions
- Verify the live Vercel site renders the latest site artifacts.
Git Publish Direct-to-main commit and push evidence.
Main Branch Publish
no changesGit publishing skipped because Shipwright is running in dry_run mode.
Commit: none
No allowed files were published in this run.
Evidence
- mode: dry_run
- pushed: false
Next Actions
- Run Shipwright in autonomous or yolo mode when changes should be committed and pushed.
Codex Provider OpenRouter provider setup and model readiness.
OpenRouter Codex
configuredModel: openai/gpt-5.1-codex-mini
Config: /home/runner/.codex/config.toml
Env key: OPENROUTER_API_KEY
Codex is configured for OpenRouter with openai/gpt-5.1-codex-mini.
Evidence
- provider: openrouter
- model: openai/gpt-5.1-codex-mini
- wire_api: responses
- OPENROUTER_API_KEY: configured
- config_path: /home/runner/.codex/config.toml
Next Actions
- Run Codex with OPENROUTER_API_KEY available in the environment.
Experiment Subjects Subject metadata and current recommendations.
Shipwright A/B Lab
Question: Should the experiment console optimize for operator confidence or fast winner selection?
Winner: Variant A - Evidence-first surface
Shipwright should run Shipwright A/B Lab as an A/B subject with Variant A: Evidence-first surface.
remote
Package: shipwright
Package manager: npm
Lockfile: package-lock.json
Install: npm ci
Framework: static-site
Scripts: vercel deploy
Onboarding Flow Experiment
Question: Should onboarding lead with a guided checklist or an autonomous summary?
Winner: Variant A - Guided checklist
Shipwright should run Onboarding Flow Experiment as an A/B subject with Variant A: Guided checklist.
metadata only
Package: shipwright
Package manager: npm
Lockfile: package-lock.json
Install: npm ci
Framework: static-site
Scripts: none
Pricing Page Experiment
Question: Should pricing lead with a simple plan comparison or proof from judge outcomes?
Winner: Variant B - Judge-proof pricing
Shipwright should run Pricing Page Experiment as an A/B subject with Variant B: Judge-proof pricing.
metadata only
Package: shipwright
Package manager: npm
Lockfile: package-lock.json
Install: npm ci
Framework: static-site
Scripts: none
Experiment Subject Plan Preparation plan for each generated subject.
Shipwright A/B Lab
Repository: https://github.com/matthoffner/shipwright.git
Start: npm run report
Checks: none
Next Actions
- Keep validating the generated website before using it as the baseline for other experiment subjects.
Onboarding Flow Experiment
Repository: https://github.com/matthoffner/shipwright.git
Start: npm run report
Checks: none
Next Actions
- Keep validating the generated website before using it as the baseline for other experiment subjects.
Pricing Page Experiment
Repository: https://github.com/matthoffner/shipwright.git
Start: npm run report
Checks: none
Next Actions
- Keep validating the generated website before using it as the baseline for other experiment subjects.
Target Checkouts Repository and workspace materialization evidence.
Shipwright A/B Lab
selfRepository: none
Workspace: .
Secret: none
Evidence
- target is generated by this repository
Onboarding Flow Experiment
selfRepository: none
Workspace: .
Secret: none
Evidence
- target is generated by this repository
Pricing Page Experiment
selfRepository: none
Workspace: .
Secret: none
Evidence
- target is generated by this repository
Credential Readiness Secret and credential checks for the run.
Shipwright A/B Lab
not requiredSecret: none
Repository: none
Evidence
- No repository credential is required for this target.
Next Actions
- Keep this subject in the default experiment path.
Onboarding Flow Experiment
not requiredSecret: none
Repository: none
Evidence
- No repository credential is required for this target.
Next Actions
- Keep this subject in the default experiment path.
Pricing Page Experiment
not requiredSecret: none
Repository: none
Evidence
- No repository credential is required for this target.
Next Actions
- Keep this subject in the default experiment path.
Product History Changelog-derived product memory.
Autonomous Dogfood Runtime
- Added: Add Typed Codex Provider Setup — Add typed codex provider setup.
- Added: Surface Codex Contract Failures — Surface codex contract failures.
- Added: Lane decision artifacts — made orchestration decisions inspectable through structured metrics.
- Added: Codex dogfood writes — enabled bounded Codex improvements inside the Shipwright workflow.
- Added: Direct-to-main dogfood — let Shipwright commit its own verified dogfood output to `main`.
Shipwright Product Updates
- Added: Add Variant Judge Runs — Add variant judge runs.
- Added: Pivot Shipwright To A/B Experiment Platform — Pivot shipwright to ab experiment platform.
- Added: Add A/B Consensus Worker Edit Recipes — Add ab consensus worker edit recipes.
- Added: Surface A/B Consensus Execution Metadata — Surface ab consensus execution metadata.
- Added: Add A/B Consensus Handoff Packets — Add ab consensus handoff packets.
Consensus Work Orders
- Added: A/B consensus work orders — turns ready consensus winners and blocker-clearing tasks into assignable worker packets above the detailed lanes.
- Added: A/B consensus priority backlog — ranks consensus work orders with priority, effort, and next verification commands so workers can act from the generated queue.
- Added: A/B consensus gate checks — shows decision, promotion, visual, dogfood, and judge-matrix gates for each consensus handoff.
- Fixed: A/B consensus work orders — turns ready consensus winners and blocker-clearing tasks into assignable worker packets above the detailed lanes.
- Fixed: A/B consensus readiness actions — keeps blocked target summary cards pointed at unblock work instead of promotion handoffs.
Product History Surface
- Added: Product outcome changelog sections — splits same-day changes into DevBox-style outcome sections so the website can show product history without relying on journal entries.
- Added: Product history digest — grouped changelog outcomes for the website and reduced journal output to compact audit metadata.
- Added: DevBox-style changelog — made `CHANGELOG.md` the human-facing product history and kept journals as audit evidence.
- Fixed: Artifact-only dogfood journals — keeps dogfood journal entries in workflow evidence artifacts so tracked history stays focused on the changelog.
Product History Quality
- Fixed: Changelog history window — keeps the automated changelog scan wide enough to preserve older product outcomes during dogfood refreshes.
- Fixed: Product history classification — keeps new outcomes in named DevBox-style changelog sections instead of the generic product-updates bucket.
- Fixed: Changelog synthesis quality — tightened deterministic summaries so new product entries stay useful instead of echoing commit subjects.
- Fixed: Product history grouping — keeps UI workspace changes summarized as DevBox-style product history instead of noisy commit echoes.
Autonomous Deployment Evidence
- Added: Website evidence artifact — uploads the generated site, screenshots, and machine-readable consensus artifacts when Vercel cannot publish the report.
- Added: Deploy status evidence — records Vercel readiness and deploy failures as structured evidence so stale live sites do not look current.
- Fixed: Deploy status evidence — records Vercel readiness and deploy failures as structured evidence so stale live sites do not look current.
Product History Benchmark
- Added: Product history section guard — flags oversized changelog sections so Shipwright keeps copying DevBox's concise outcome history instead of growing giant buckets.
- Added: Current-state digest — summarizes what changed, what is ready, what is blocked, and next actions from evidence artifacts instead of journal prose.
- Added: DevBox changelog benchmark — scores Shipwright product history against DevBox-style outcome sections, category grouping, source traceability, and journal-noise removal.
- Fixed: Product history section guard — flags oversized changelog sections so Shipwright keeps copying DevBox's concise outcome history instead of growing giant buckets.
Consensus Experiment Design
- Added: A/B consensus experiment packets — adds assignment, allocation, event contract, and readout state to each UI consensus handoff.
- Added: A/B consensus variant comparison — exposes winner, runner-up, margin, vote split, thesis, and risk for every consensus queue item.
- Added: A/B test consensus plans — published hypotheses, split, metrics, guardrails, decision rules, and results for each UI consensus test.
- Added: A/B consensus scorecards — added weighted criteria, confidence, and machine-readable scorecards for UI consensus.
- Added: UI experiment consensus artifacts — added group-vote poll synthesis for dogfood UI decisions.
Consensus Response Artifacts
- Added: Consensus response packets — packages each UI consensus target as a group-vote question, majority, dissent, evidence checklist, and copyable response prompt.
- Added: Consensus response matrix — publishes group-vote judge alignment, criterion deltas, Playwright evidence, and runtime evidence for each UI consensus subject.
- Added: UI consensus report — promoted consensus decisions into the generated Shipwright report.
- Fixed: Consensus response matrix — publishes group-vote judge alignment, criterion deltas, Playwright evidence, and runtime evidence for each UI consensus subject.
Experiment Operator Plan
- Added: Experiment blocker diagnosis — gives blocked app targets one primary unblock path with next action and verification command before the raw evidence list.
- Added: Experiment status board — merges target inspection, credentials, runtime, screenshots, and consensus handoffs into one per-app readiness view.
- Added: Experiment subject plan — published preparation, verification, credential, blocker, and next-action plans for each A/B subject.
- Fixed: Experiment blocker diagnosis — gives blocked app targets one primary unblock path with next action and verification command before the raw evidence list.
- Fixed: Experiment subject plan — published preparation, verification, credential, blocker, and next-action plans for each A/B subject.
Consensus Blocker Clarity
- Added: Consensus blocker clarity — separates blocked targets from failing checks so the A/B consensus queue matches the top current-state digest.
- Fixed: Consensus blocker clarity — clears blocker language from ready-for-build consensus cards when captured runtime evidence already proves the target is reviewable.
- Fixed: A/B consensus lane layout — gives blocker-heavy consensus lanes enough room for readable evidence and worker handoffs.
- Fixed: Unique A/B consensus subjects — keeps `site/ab-tests.json` from counting the same generated surface twice.
Consensus Decision Workspace
- Added: UI consensus cockpit — added target tabs, decision panels, vote/rubric details, dissent, and copyable worker handoffs to the generated website.
- Added: A/B consensus operator lanes — adds clear-first, ready-to-ship, and watch lanes with one recommended worker action for the consensus UI.
- Added: A/B consensus queue — ranks consensus items into ship, blocked, and watch states using test plans, judge matrices, and dogfood readiness.
- Added: Consensus board — turns A/B consensus plans into ready-for-build and needs-more-signal lanes on the generated website.
- Added: UI consensus workspace — turned the report-style consensus section into a judge-panel decision workspace with options, rubric, votes, responses, and surface signals.
DevBox Changelog Benchmark Checks that keep the product history readable.
6/7 DevBox-style product history checks pass.
Shipwright should keep copying the useful DevBox split: changelog for product history, journal for audit evidence.
- Dated sections name product outcomes.
- Entries are grouped under Added, Changed, and Fixed.
- Bullets use a bold outcome label followed by a short user-facing explanation.
- Source commits remain visible, while routine run journals stay audit-only.
Dated Outcome Sections pass
18 dated product outcome sections are available.
Evidence
- Autonomous Dogfood Runtime
- Shipwright Product Updates
- Consensus Work Orders
- Product History Surface
Next
- Keep grouping changes by named product outcome instead of dumping every run into one feed.
Added Changed Fixed Grouping pass
2 changelog categories are represented: Added, Fixed.
Evidence
- Added
- Fixed
Next
- Preserve DevBox-style Added, Changed, and Fixed category headings as the product matures.
Concise Product Bullets pass
92/92 entries use the DevBox-style bold outcome plus one-line explanation.
Evidence
- Add Typed Codex Provider Setup
- Surface Codex Contract Failures
- Lane decision artifacts
- Codex dogfood writes
Next
- Rewrite vague commit-derived entries into product outcome bullets before publishing.
Source Traceability pass
92/92 entries retain source commit references.
Evidence
- Add Typed Codex Provider Setup: f8681de
- Surface Codex Contract Failures: 14022ba
- Lane decision artifacts: 8d809ad
- Codex dogfood writes: 88a46f8
Next
- Keep source commit links on every generated changelog bullet.
Journal Noise Removed pass
No routine dogfood or journal-only entries are promoted into product history.
Next
- Keep dogfood run bookkeeping in metrics/journal artifacts and reserve CHANGELOG.md for product outcomes.
Named Outcomes pass
Section titles name product outcomes instead of generic update buckets.
Evidence
- Autonomous Dogfood Runtime
- Shipwright Product Updates
- Consensus Work Orders
- Product History Surface
Next
- Prefer headings like DevBox's V5 onboarding or duplicate-MR guardrail sections over generic update labels.
Focused Section Size fail
Largest changelog section has 15 entries; DevBox-style sections stay small and outcome-specific.
Evidence
- Shipwright Product Updates: 15 entries
- Autonomous Dogfood Runtime: 12 entries
- Consensus Experiment Design: 6 entries
- Consensus Work Orders: 5 entries
Next
- Split oversized sections into narrower dated outcomes before the website treats product history as healthy.
Run Audit The latest workflow journal entry.
- Writer
- matthoffner
- Repo
- matthoffner/shipwright
- Mode
- yolo
- Outcome
- would_run
- Lane
- intake
- Task
- intake:advance_runtime
- Run
- https://github.com/matthoffner/shipwright/actions/runs/27900743899
Operating Model How Shipwright decides when to plan, write, or stop.
Dry runs explain the next move before Shipwright writes code.
Autonomous runs turn bounded work into verified changes.
YOLO mode keeps shipping while the changelog carries product history.